具有不同震级数据标准化
这个例子说明了如何使用规范化,以改善与散乱数据插值结果的GridData。标准化可以提高在某些情况下,插值结果,但在另会危及解决方案的准确性。是否使用标准化是由基于数据的性质的判断进行插值。
优点:标准化你的数据可以潜在地提高当自变量有不同的单位和显着不同的尺度插值结果。在这种情况下,缩放输入具有类似的量值可以提高插值的数值方面。其中归一化是有益的一个示例是如果
X表示发动机转速,单位为rpm从500到3500,和ÿ表示从0到1的鳞片发动机负荷X和ÿ数量级的几个订单不同,他们有不同的单位。注意事项:使用标准化数据时,如果自变量具有相同的单位,即使变量的尺度是不同的警告。与同一单元中的数据,归一化扭曲通过添加定向偏置,从而影响到底层三角测量并最终损害了内插的准确度的解决方案。其中归一化是错误的一个例子是,如果这两个
X和ÿ代表位置,并有单位为米。缩放X和ÿ不平等不建议,因为正东10米应该是正北空间的相同至10μm。
创建一些样本数据,其中值ÿ比在较大规模的订单数X。假使,假设X和ÿ有不同的单位。
X =兰特(1500)/ 100;Y = 2 *(兰特(1500)-0.5)* 90。Z =(X * 1E2)^ 2。
使用样本数据来构建的查询点的网格。插值对电网的样本数据得出结果。
X = linspace(分钟(x)中,MAX(X),25);Y = linspace(分钟(Y),最大值(Y),25);[XQ,YQ] = meshgrid(X,Y);ZQ =的GridData(X,Y,Z,XQ,YQ);plot3(X,Y,Z,“莫”)保持上目(XQ,YQ,ZQ)xlabel('X')ylabel('Y')保持离
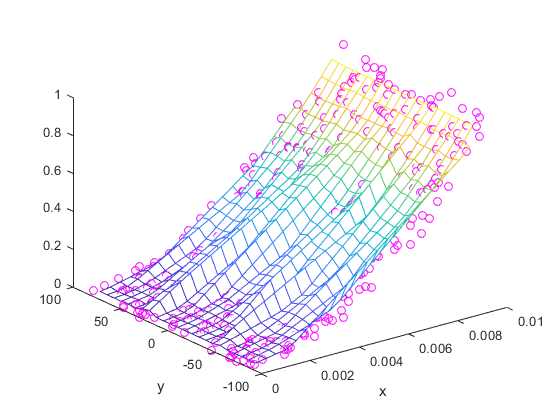
所产生的结果的GridData是不是很顺畅,似乎是嘈杂。在独立的变量不同规模有助于此,由于在一个变量的大小的微小变化可导致在其它变量的大小大得多的变化。
以来X和ÿ有不同的单位,他们归,使他们具有类似的量值应有助于产生更好的效果。使用规范化的样本点ž-scores和使用再生插值的GridData。
%正常化采样点X =正常化(X);Y =正常化(Y);%重新生成网格X = linspace(分钟(x)中,MAX(X),25);Y = linspace(分钟(Y),最大值(Y),25);[XQ,YQ] = meshgrid(X,Y);%插值并绘制ZQ =的GridData(X,Y,Z,XQ,YQ);plot3(X,Y,Z,“莫”)保持上网格(xq, yq zq)
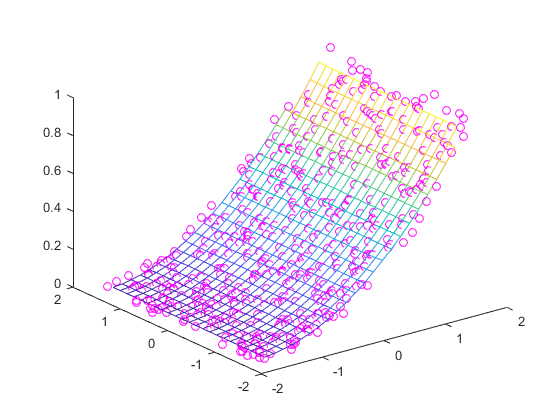
在这种情况下,归一化所述样本点允许的GridData计算更平滑的解决方案。
也可以看看
您还可以选择从下面的列表中的网站:
